



[Frontier #19] 리벨리온 기업분석 완성판
드디어... 리벨리온 기업분석 완료. Pinpoint Research에서 만나보실 수 있습니다.

재정비의 시간을 가지고 다시 시작합니다. 꾸준히 좋은 글로 찾아뵙겠습니다. 찾아주신 분들께 진심으로 감사 인사를 드립니다.


프런티어 by 김도엽은 기술과 창업의 최전선에 대한 제 시각을 공유하는 뉴스레터입니다. 최신 글을 이메일로 받아보시려면 구독하세요! 547명의 독자와 함께하고 있습니다.
리벨리온 분석 리포트는 6월부터 준비해온 프로젝트인데, 이제야 끝맺게 되었습니다. Frontier에서는 경쟁사와 결론 부분을 프리뷰로 제공합니다. 전문을 읽고 싶다면?

competition
동사는 크게 세 그룹의 경쟁자와 맞붙는다: 1) 기존 팹리스 강자, 2) 데이터 센터 업체, 그리고 3) 스타트업이다.
1) traditional fabless firms
이 그룹에는 NVIDIA, AMD와 Qualcomm이 속한다. NVIDIA는 시장의 지배자이다: 학습과 추론, 모든 면에서 압도적인 성능과 편의성을 제공하고 있다. 이의 기반에는 15+년간 쌓아온 HW 디자인 노하우와 CUDA 환경을 기반으로 한 높은 개발자 경험(DX)이 있다.
제품 라인업의 경우, 데이터 센터에 들어가는 최고 성능 H100 (플레그십, +300W 급), A100 (구형)과 TCO에 집중한 L4 (75W 급)가 대표적이다. 그러나 AI 칩만 생각하면 오산이다. NVIDIA의 설계 역량과 Mellanox와의 M&A를 통하여 데이터 센터에 특화된 Grace CPU와 Bluefield DPU도 만들고 있다. 이에 SW 역량이 더해져 데이터 센터에 필요한 모든 것을 모아 하나의 “solution”으로 대형 엔터프라이즈에 판매하고 있다.
이에는 AI에 집중된 NVIDIA DGX 클라우드 플랫폼이 대표적이며, 타 엔터프라이즈 소프트웨어와 AI를 함께 구동할 수 있는 EGX와 슈퍼 컴퓨터 HGX 또한 라인업에 포함되어있다.
AMD의 경우, MI300 시리즈를 통하여 NVIDIA의 H100 / A100 시리즈를 정조준하고 있다. AMD는 CPU - GPU - memory를 통합 배치한 설계를 채택하여 성능을 끌어올렸다. 기존에는 SDK (드라이버, 컴파일러) 문제 때문에 칩의 성능과 관계없이 활용하기 어려웠으나, 올해 상반기 중 해결된 것으로 보인다. MosiacML에 따르면 MI250 칩(구형)은 모델을 학습시키는데 A100과 유사한 성능을 보여주었다고 한다.
최근 발표에 따르면, MI300 칩 (+500W 급)의 생산을 램프업하고 있다고 한다. 데이터 센터 CPU에서 인텔의 점유율을 유의미하게 깎아내고 있는 레드팀 (AMD)이기에, MI 시리즈를 통한 AI 반도체 도전은 더더욱 의미 있어 보인다.
NVIDIA와 AMD의 경쟁은 학습과 최고 성능 데이터 센터에 맞추어져있다면, Qualcomm은 이와 반대로 엣지컴퓨팅에 초점을 둔 고효율 칩을 만들고 있다. Qualcomm이 모바일 AP 강자이기에 이는 자연스러운 움직임으로 보이며, 동사의 ATOM 칩과 가장 유사한 포지셔닝의 칩이 Qualcomm의 AI 100 (75W 급)이다.
ATOM과 동일 선상에서 벤치마크 성능을 비교하면 어떨까? MLPerf v3.0 Inference: Edge, BERT(자연어 처리)에서 성능을 비교해 보자. NVIDIA는 L4 칩, Qualcomm은 AI 100 PCIe가 동급이다 (75W 급).
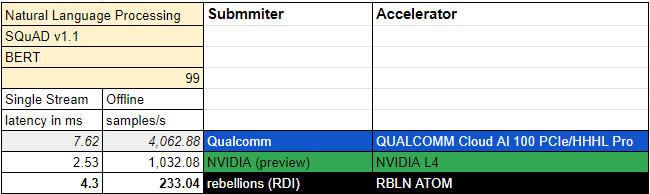
당연하게도 Single Stream 성능은 L4가 우위이지만, ATOM이 AI 100 PCIe 보다 좋은 성능을 보여주었다. Offline samples/s의 경우 동사의 칩이 가장 낮은 성능을 보여주었다. 여기까지는 좋은 성과로 보일 수 있다.
동사가 Inference: Datacenter 부문에 샘플을 제출하지 않았다는 점에 주시하자 (Edge 샘플이 유일하다). MLPerf 논문에는 각 테스트 시나리오에 관해 설명이 제공된다.
Single Stream: The single-stream scenario represents one inference-query stream with a query sample size of 1, reflecting the many client applications where responsiveness is critical. An example is offline voice transcription on Google’s Pixel 4 smartphone.
Server: The server scenario represents online applications where query arrival is random and latency is important. Almost every consumer-facing website is a good example, including services such as online translation from Baidu, Google, and Microsoft. For this scenario, queries have one sample each, in accordance with a Poisson distribution.
Offline: The offline scenario represents batch-processing applications where all data is immediately available and latency is unconstrained. An example is identifying the people and locations in a photo album.
동사는 데이터 센터에 칩을 납품하는 것을 목표로 하고 있기에 Inference: Edge, Single Stream에서의 성능보다 Inference: Datacenter, Server에서의 성능이 중요하다. 그러나 동사가 이 부문에 점수를 제출하지 않았기에 데이터 센터 환경에서의 경쟁력에 대해 의문이 남는다.
이렇듯, MLPerf만으로 칩과 칩의 성능을 완벽하게 비교할 수 없다. 테스트 환경에 따라 성능의 차이가 명확하기에, 특정 환경에서 NVIDIA의 레거시 칩을 이겼다고 “엔비디아를 제쳤다”라 말하는 자극적인 기사들에 눈살이 찌푸려지는 것이 사실이다. 타 스타트업은 v3.0 벤치마크에 업로드를 하지 않았기에 직접적인 비교는 불가능하다.
v3.1 벤치마크가 올해 9월 11일에 업로드 되었는데, 동사는 결과를 업로드 하지 않았다. 이번부터 LLM이라는 카테고리가 신설되어 GPT-J 모델에서의 추론 성능도 알 수 있게 되었다. 동사가 추후 MLPerf Server 카테고리, LLM 분야에서 좋은 성과를 얻는다면, 글로벌 경쟁력을 갖추고 있다고 확신할 수 있을 것이다. 그 전까지는: NVIDIA is KING.
2) Datacenter Firms
현재 데이터 센터 3사: 구글의 Google Cloud Platform, 아마존의 Amazon Web Services, 그리고 마이크로소프트의 Azure은 모두 자체적으로 AI 하드웨어 가속기를 개발 중에 있다.
대표적으로 구글의 TPU (Tensor Processing Unit)은 2013년부터 개발에 착수하여 10여년 넘게 업그레이드하였다. 최초에는 큰 성과를 얻지 못했으나 긴 시간 투자를 한 결과, 구글은 NVIDIA에서 독립적인 AI 컴퓨팅을 할 수 있는 능력을 갖추었다. 대표적으로, 구글의 초거대 AI, PaLM (540M param) 모델이 6144개의 TPUv4 (현재 v5가 최신) 칩을 결합해 학습되었다.
구글의 TPU는 외부에 판매하지 않고 있으나, 구글 클라우드를 통하여 임대해 사용할 수 있다. 구글은 이미 자체적인 시스템을 갖추고 있고, TPUv5 / TPUv5e 칩의 성능 또한 높기에 (MLPerf v3.1 기준, TPUv5e는 NVIDIA L4보다 좋은 Server LLM 퍼포먼스를 보여준다) 동사의 칩을 구매할 일은 없을 것이다.
아마존은 2015년 이스라엘의 AI 팹리스 스타트업, 안나푸르나 랩스를 약 4000억에 인수했다. 이후 Trainium이라는 학습용 칩과 Inferentia라는 추론용 칩을 개발해 왔다. 외부적으로 공개된 내용이 많지는 않으나, Inferentia v1은 4개의 코어와 8GB DRAM, 128TOPS (ATOM과 동일)의 컴퓨팅 파워가 탑재된 칩이다. Inferentia v2는 2개의 코어와 32GB의 HBM, 최대 190TFLOPS의 컴퓨팅 파워를 제공한다. 이는 AWS를 통해 EC2 inf1과 inf2 인스턴스로 고객사에 제공된다.
가장 베일에 싸여있는 것은 마이크로소프트의 Athena 칩이다. 23년 TSMC 5nm로 tape-out을 진행한 것으로 알려진 신상 칩이지만, 2019년부터 개발해 왔다고 한다. 곧 다가올 Ignite 컨퍼런스 (23년 11월)에서 이를 공개하고, 24년 Azure를 통해 고객에게 제공될 계획이라 발표되었다.

구글 TPU의 압도적 성능에 비해 아마존과 마이크로소프트 자체 AI 실리콘의 성능은 알기 힘들다. 구글과 아마존의 학습/추론 칩 분리 전략을 통해 장기적으로 AI 칩 시장이 고성능 고TCO, 저성능 저TCO 칩으로 분리될 것을 예상할 수 있겠다.
3) Startups
눈여겨볼 경쟁자는 Sambanova, Tenstorrent, 그리고 Cerebras로 보인다.
Sambanova
Sambanova는 가장 많은 펀딩을 받은 AI 팹리스 (over $1B funded) 이며, 기업가치 5조 이상의 평가를 받고 있다. CGRA 기반의 설계(Reconfigurable Data Flow Unit)를 통해 학습과 추론을 모두 담당할 수 있는 칩을 만들었으나, 이를 따로 판매하지 않고 클라우드 솔루션으로만 제공한다.
나아가서, 클라우드 유저들에게 SW suite를 제공함으로써 유저들이 쉽고 빠르게 모델을 학습하고 서빙할 수 있게 돕는다. 이런 방향성은 NVIDIA가 DGX와 함께 SW solution을 제공하는 것과 유사하다.
Sambanova는 칩을 외부에 판매하지 않기에, 별도의 MLPerf 벤치마크 없이 자체 서버에서의 성능만을 공개하고 있다. 현재까지는 연 300억 가량의 매출을 내고 있으나, 대형 고객사를 확보했다는 소식은 딱히 들리지 않고 있다.
Tenstorrent
가장 흥미로운 접근을 택한 AI 팹리스 기업이다. 전설적인 반도체 설계자 짐 켈러가 이끄는 스타트업으로, 최근 삼성전자와 현대자동차에 1000억 펀딩을 받으며 $2B의 기업가치를 인정받았다.
RISC-V 라는 새로운 ISA를 기반으로, sparse한 연산이 많아질 것을 염두로 한 설계를 하고 있다. 확연히 타 AI 팹리스와는 다른 행보, 그리고 압도적인 팀을 갖추고 있어 앞으로의 행보가 기대된다. BM은 동사와 유사하나, 이들은 추론과 학습 둘 다 가능한 칩을 만들고 있다는 점에서 차이가 존재한다.
Tenstorrent 역시 대형 고객사와의 계약(매출 30억 이하)이나, MLPerf 벤치마크가 공개된 바 없어, 명확하게 성능을 파악하기 힘들다.
Cerebras
거대한 웨이퍼에 대량의 on-chip SRAM (40GB)과 compute unit을 새김으로 초대형 반도체를 만들고 있는 회사이다. $4B에 가까운 valuation을 받고 있으며, AI뿐 아닌, scientific compute에 필요한 병렬 컴퓨팅을 제공하고 있다.

Jasper, GlaxoSmithKline, AstraZeneca 등의 고객사를 확보했다는 점(매출 약 500억)이 인상적이다. Hugging Face로 자사 칩에서 효율적으로 학습 가능한 GPT (Cerebras-GPT)를 공개하며 학습 효율을 과시하고 있다.
특별한 아키텍처를 기반으로 높은 효율을 보여주고 있으나, SRAM 기반의 설계 때문에 GPT-4 급의 모델을 경제적으로 학습할 수 있을지 의문이 존재한다.
이외에도 Graphcore, Groq, Mythic 등이 대량의 펀딩을 받았으나, 앞의 두 회사는 SRAM 기반의 설계에서 오는 문제점, 그리고 후자는 상용화에 난항을 겪고 있다.
한국에서의 경쟁사는 SKT의 spinoff 벤처인 사피온과 네이버 D2SF의 펀딩을 받으며 네이버 클라우드와 협업하는 퓨리오사이다. 양사 모두 500~1000억 펀딩을 받으며 높은 기업가치를 인정받았다.

양사 모두 MLPerf서 좋은 성능을 얻었다고 홍보하고 있으나, 동사와 마찬가지로 톺아보면 기대 이하이다. 퓨리오사는 21년 MLPerf에서 엔비디아를 눌렀다고 주장하고 있으나, 역시 서버 환경이 아닌 Edge: Single Stream 퍼포먼스를 비교한 것이다. 또한 트랜스포머가 아닌, CNN 기반의 모델에서 성능을 비교했기에, 현재 시장 환경에서 유의미한 세일즈 포인트가 될 수 없다.
사피온은 유일하게 Server 환경에서 성능을 업로드하였으나, 마찬가지로 CNN 기반 모델에서 성능만 업로드 하였다. 동사가 유일하게 트랜스포머 모델 성능을 업로드하였기에, 벤치마크 기준으로 상대적 엣지를 지닌다고 할 수 있다.
앞서 언급했듯이 벤치마크 성능만으로 기술력을 평가하기 어렵다. 오히려, 퓨리오사/사피온 양사가 동사에 비해 시장 진입이 느리다는 점이 핵심이다. 동사의 ATOM은 KT 데이터 센터에 탑재된 반면, 창업 7년 차를 맞은 퓨리오사는 아직도 자사 칩을 데이터 센터에 대량으로 공급하지 못했다 (협약 단계가 대부분). 사피온은 작년 (2022년) 스핀오프하였고, 올해 6월 NVIDIA 출신의 CTO를 영입했기에 앞으로가 궁금해진다.
ending thoughts
동사에 대해 공부하며, 반도체 기업을 세운다는 것이, 그리고 위대한 기업을 일구는 것이 얼마나 어려운지 체감할 수 있었다.
NVIDIA의 경우, 1990년대부터 강력한 해자를 쌓아온 회사이고, 수많은 혁신을 통해 살아남았다. 최초로 시뮬레이션 기반의 설계를 채택해 6개월 단위로 칩을 찍어내며 경쟁자들을 제쳤고, 그래픽 카드가 CPU에 흡수되지 않도록 programmable shader라는 개념을 발명하여 게임에 생명을 부여했다.
똑똑하게도 NVIDIA는 GPU라는 명칭을 최초로 사용했고, GeForce와 함께 이는 게이밍과 synonymous한 브랜드가 되었다. 나아가서 GPU를 환경에 관계없이 구동할 수 있게 만들기 위해 backwards compatable 한 드라이버를 최초로 개발하여 무료 공개하였다.
소비자뿐 아니라 개발자를 위해 SDK를 개발하였고, 이는 나아가 CUDA라는 유일무이한 프로그래밍 환경으로 발전했다. NVIDIA의 이야기를 모른다면, 게이밍 GPU 만들다가 운 좋게 잘 된 회사처럼 보일 수 있지만, NVIDIA는 GPU의 아버지, 병렬 연산의 아버지, 컴퓨팅 환경 개발의 아버지이다.
NVIDIA가 주어진 것에 만족하지 않고, 미래를 보고 한발 앞서 움직였기에 세상이 그들에게 찾아온 것이다. 젠슨 황은 이미 다음 페이지를 보고 있다.
삼성전자가 메모리 시장의 latecomer에서 글로벌 리더가 된 이야기도 전설적이다. 기반이 전혀 없는 상태에서 시작했으나, 공격적인 투자와 인재 영입을 통해 R&D 시간을 압축했다.
당시 1, 2위를 다투던 일본 기업들이 “트렌치” 구조를 선택하여 메모리를 쌓을 때 “스택” 구조를 채택하며 큰 베팅을 했다. “스택” 구조는 장기적으로 메모리 확장에 용이했고, “트렌치” 구조를 채택한 일본 기업들은 대부분 몰락했다.
반도체 불황에도 투자액을 늘리는 역발상을 통하여 사이클이 다시 올라왔을 때 손쉽게 생산을 램프업할 수 있었고, 1993년부터 30년 동안 메모리 반도체 점유율 세계 1위 자리를 지키고 있다.
처음과 반대로, NVIDIA는 스타트업이 아닌 거인이다. 동사에게 아직 명확한 해자는 없지만, 리스크를 지며 큰 배팅을 하기엔 가장 적합한 위치에 있음은 분명하다. 동사의 사명은 “Rebellions” 즉, 반란자이다. AI 컴퓨팅 시장에 반항을 일으킬 만한 무언가를 만들 수 있길 바란다.
한국에서 빅테크, Hard Startup도 크게 될 수 있다는 것을 보여주길. 리벨리온을 응원한다!
기업 분석 다음 글은 팀원 주현님과 함께한 APR 리포트가 될 예정입니다. 그 글까지 완성되고 나면 디지털 헬스케어, IP, 게임 산업을 중점으로 공부하며 인사이트를 공유할 생각이에요. What I Read This Week 컨텐츠도 고려하고 있고요! 자주 찾아뵙겠습니다.
프런티어 by 김도엽을 읽어주셔서 감사합니다.