



[Frontier #15] 리벨리온, Next 삼성을 꿈꾸다? 기업분석 (上)
삼성의 바통을 잇겠다고 말하는 기업, 리벨리온의 기업분석

안녕하세요, 독자 여러분. 휴가 기간 글을 자주 올리지 못해 죄송합니다. 다시 적응하며 기존 업로드 사이클로 돌아가 보도록 하겠습니다.
휴가 동안 멋진 분들을 많이 만나면서 뉴스레터를 쓰기 너무 잘했다는 생각이 들었습니다. 제가 가고자 하는 길에 대한 확신도 강해졌고요.
오늘은 엔지니어라면 한 번은 관심을 가져볼 법한, 설레는 회사 : 리벨리온에 대해 분석해 보았습니다. AI에 깊은 관심이 있다 보니, 꼭 톺아보고 싶은 기업이었습니다. 삼성의 바톤을 잇는다는 원대한 목표를 가지고 세계에 출사표를 던지는 반도체 기업. 과연 새로운 팹리스 강자가 탄생할 수 있을까요?


프런티어 by 김도엽은 기술과 창업의 최전선에 대한 제 시각을 공유하는 뉴스레터입니다. 최신 글을 이메일로 받아보시려면 구독하세요! 443명의 독자와 함께하고 있습니다.
thesis
the age of ai
AI의 시대가 온다.
The development of AI is as fundamental as the creation of the microprocessor, the personal computer, the Internet, and the mobile phone. It will change the way people work, learn, travel, get health care, and communicate with each other. Entire industries will reorient around it. Businesses will distinguish themselves by how well they use it.
AI가 인류의 역사를 바꿀 파급력을 지니고 있다는 건 점점 더 분명해지고 있다. 게이츠가 말한 대로, AI는 우리가 일하고, 공부하고, 여행하고, 소통하고, 의료 서비스를 제공받는 방식을 바꿀 것이다. 나아가 산업의 구조는 AI에 맞춰 재구성될 것이다. 우리는 그 시작점에 서 있다.
그렇다면 인공지능은 정확히 어떻게 작동하는 것일까?

inference load
AI는 크게 두 단계로 작동한다: 학습과 추론. 학습은 데이터를 통해 배우는 과정이다. 추론은 배운 것을 토대로 문제를 푸는 것이다.
인공지능은 뇌의 지능을 흉내 낼 수 있도록 설계되었기에, 유사한 부분이 존재한다. 간소화해서 비교해보자: 인간은 새로운 정보를 감각기관으로 입수하고, 그에 따라 뉴런에 변화가 생기며 학습한다. 인공지능은 개발자들이 제공한 데이터를 기반으로, 매개변수(파라미터)를 조정하며 학습한다. 즉, 학습은 주어진 정보를 표현하기에 가장 적합한 함수를 찾기 위해 함수 속의 변수(파라미터)를 조정하는 과정이다.
추론은 조금 다르다. 인간은 자연스럽게 새로운 정보를 배우는 것과, 기존의 지식을 기반으로 새로운 문제를 푸는 것을 넘나들 수 있지만, 인공지능 모델은 그렇지 못하다. AI는 추론 시 파라미터를 고정한 상태에서 문제를 푼다. 인간으로 치면, 지식을 인출할 때 뉴런의 상태를 고정하는 것이다.
예로, 연구자들이 GPT에 데이터를 주고 똑똑하게 만드는 과정이 학습이고, 엔드 유저가 GPT와 채팅을 하는 것이 추론이다. 이를 일반화하면, AI를 다루는 사람은 학습을 주로 하냐, 추론을 주로 하냐에 따라 연구자와 엔드 유저로 구분할 수 있다.
그동안 인공지능은 철저히 연구자 중심이었다. 화려한 언론보도와 무관하게, 일반인이 고도의 인공지능을 사용할 일은 거의 없었다. 그러나 ChatGPT가 출시되며 큰 변화가 일었다. 대중이 사용하였을 때 실질적 효용이 있는 AI 서비스가 처음으로 출시된 것이다. ChatGPT는 최단기간에 100M 사용자를 확보한 서비스가 되었고, 현재까지도 1B 이상의 페이지 방문을 유지하고 있다.
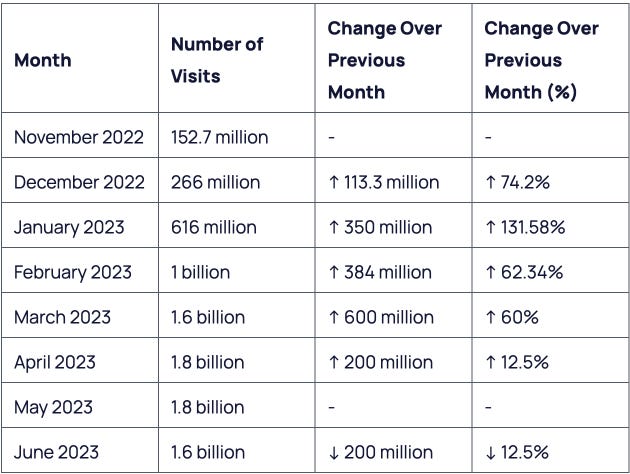
ChatGPT가 출시된지 1년도 되지 않았다는 점을 상기하면, 앞으로 얼마나 더 많은 추론향 수요가 있을지 가늠하기 어려울 정도이다.
ai hardware
추론을 위해서 필요한 것은 ChatGPT와 같은 인공지능 모델을 돌리기 위한 하드웨어이다. 기존의 CPU 구조는 막대한 양의 행렬곱을 처리하기에 부적합하기에, 인공지능 모델을 구동시키는데 필요한 연산만 모아 가속하는 AI 하드웨어 가속기 (이를 회사에 따라 [GP]GPU, NPU, TPU 등으로 부른다)가 필수적이다.
AI 하드웨어 가속의 전통 강자는 NVIDIA이고, 최근 컨퍼런스 콜에서 AI wave의 큰 수혜를 본 것이 드러났다. 그러나 최근 추론 수요가 폭발하면서, NVIDIA의 가격 정책, 높은 전력 소모, 느린 칩 공급에 피해를 보는 기업들이 속출하고 있다.
학습은 파라미터를 조정하면서 이루어지기에, 파라미터를 고정하고 진행하는 추론보다 복잡성이 높은데, 이 때문에 NVIDIA는 학습에서 거대한 해자(moat)를 보유하고 있다. NVIDIA가 학습에 필요한 소프트웨어 스택 CUDA를 수년간 연구자들과 협업하며 구축하였기에, 당분간 독점을 유지할 것으로 보인다.
반대로 추론에선 아직 기회가 존재한다. 추론에 필요한 소프트웨어는 비교적 단순하고, TOC (전력비용, 도입비용, 가성비 등을 종합한 Total Ownership Cost)의 중요도가 높아지기에, NVIDIA에 대항하는 새로운 플레이어들이 나오고 있다.
시장 판도는 대략: 기존 팹리스 강자들 (NVIDIA, AMD, Qualcomm), 데이터센터 업체들 (Microsoft, Amazon, Google), 그리고 스타트업 (동사, Cerebras 등) 간의 춘추전국 시대이다.
과연 동사는 이 거대한 글로벌 경쟁 속에서 승리할 수 있을까?
founding story
동사는 2020년, 박성현(CEO), 오진욱(CTO), 김효은(CPO), 신성호가 공동 창업했다. 4명 모두 하드웨어나 AI로 박사 학위를 수여한, 엔지니어 중심의 기업이다.

박성현 대표는 KAIST 전기 및 전자공학부(EE)를 수석 졸업 후 MIT에서 CPU 설계 (network on chip)로 석사 및 박사 학위를 수여했다. 학계를 떠난 후에는 인텔, 삼성전자, 스페이스X, 모건 스탠리에서 칩 설계를 담당했다.
오진욱 CTO는 서울대학교 EE를 졸업 후 KAIST EE에서 컴퓨터 비전 SW와 HW 설계로 석사 및 박사 학위를 수여했다. 이후 IBM에서 AI 칩 수석 설계자로 데이터센터에 들어가는 반도체를 설계했다.
김효은 CPO 역시 KAIST EE 학부를 졸업 후 동 대학원에서 VLSI 설계로 석사 및 박사 학위를 수여했다. 이후 삼성전자를 거쳐, 의료 AI 기업 루닛에서 AI 분야 총괄 및 CPO를 역임했다.
신성호 공동창업자는 서울대학교에서 AI 알고리즘 연구로 박사 학위를 받았다.
미국에서 승승장구하던 박성현 대표와 오진욱 CTO가 한국에 돌아와 팹리스 (반도체 생산은 하지 않고, 설계만 하는 기업) 기업을 차린 것이 인상적이다. 미국 최고의 기업에서 반도체 설계를 해본 두 공동창업자는 한국에서 기회를 포착했다.
아래 인터뷰 내용처럼, 파운드리, 디자인 하우스와 인재를 모두 갖추고 있는 나라는 세계에 한국, 미국, 중국, 대만밖에 없다.
박성현 대표는 “이번 성과는 삼성전자, 반도체 디자인 하우스 세미파이브 등과 함께 만든 한국 반도체 생태계의 승리”라고 강조했다. 2년 전 반도체 쇼티지 상황에서도 삼성전자와 세미파이브는 신생 기업인 리벨리온의 아톰 시제품의 제작을 맡았다. 박 대표는 “한국은 훌륭한 파운드리 기업이 있고 반도체 디자인 하우스 생태계도 강력해 리벨리온 같은 AI 반도체 스타트업이 글로벌 기업으로 성장할 수 있는 곳”
"미국도 정부에서 반도체에 투자를 많이 하지만 시장 분위기가 바뀌었어요. 반도체 설계와 개발은 공부도 오래 해야 하고 힘들다 보니 사람들이 기피하죠. 미국 대학들은 컴퓨터공학 전공과 전자공학 전공을 같이 뽑는데, 모두 소프트웨어 개발하는 컴퓨터공학으로 넘어가요. 미국은 서비스업에 AI를 접목해 돈을 잘 벌다 보니 우수 인력들이 페이스북 등 서비스 분야에 모입니다. 반면 한국은 우수 인력들이 전자공학에 지원을 많이 하죠."
박성현 대표가 타 AI 팹리스 기업과의 경쟁 우위를 한 가지 뽑으라는 질문에 인재라고 답할 만큼, 팀에 대해 강한 믿음을 가지고 있다. 처음에는 금융 회사가 필요로 하는 칩을 만드는 것에서 시작했으나, 확신이 강해짐에 따라 더 큰 꿈인 AI 추론 칩 시장 장악을 목표로 하게 되었다고 한다.
product
ION

동사는 금융업에서 이용되는 초저지연(Ultra Low Latency, 이하 ULL) 칩을 설계에 도전장을 던지며 출범했다. 퀀트 투자를 할 때 경쟁자보다 정보를 빠르게 처리해야 좋은 거래를 낚아챌 수 있기에, 특화된 칩이 필요하다. 또한, 최근 딥러닝 알고리즘을 이용한 트레이딩이 늘어남에 따라, 이를 구동할 수 있도록 설계했다.
박성현 대표는 모건 스탠리에서 ULL FPGA 개발을, 오진욱 CTO는 IBM에서 인공지능 NPU 설계를 리드했기에 이런 선택은 자연스럽게 느껴진다. 처음부터 모험하기보다는 공동 창업자들이 가장 잘하는 것을 조합해 첫 제품을 내놓은 것이다.
2021년 11월에 출시하였고, 현재 월스트리트에서 테스트받고 있다고 한다. 체결된 계약이 없다는 점에서 아쉬움이 있지만, ION을 테이프-아웃한 (파운드리에 설계도를 전달) 것은 후속작 ATOM을 만드는데 좋은 거름이 되었다.
스펙은 다음과 같다. TSMC 7nm 공정으로 제작되었고, FP16에서 최대 4TFLOPs, INT8/4에서 최대 16/32TOPs의 연산을 수행할 수 있다. 최대 TDP (Thermal Design Power. 최대 로드에서 소비되는 에너지양)는 2~6W이다. 몇 가지 특징은:
FP16과 INT8/4/2 함께 지원
mixed precision. FP16은 소수점까지 다룰 수 있는 연산이고, INT8/4/2는 정수형 연산이다. 이를 동시에 지원하는 국내 팹리스는 아직 동사밖에 없다.
학습을 갓 마친 모델은 소수점 연산으로 작동되나, 양자화 (quantization)을 통해 FP16 → INT8/4/2로 변환할 수 있다. 이를 통해 모델 크기 축소, 연산량 감소, 효율적인 하드웨어 활용을 도모할 수 있으나 성능에 부정적 영향을 준다.
작은 성능 감소라 체감이 크지 않을 수 있으나, Google이 AI 하드웨어 가속기를 개발하며 작성한 TPUv4i 논문에 의하면, 성능이 높아질수록 1%의 하락이 더 크게 체감되기에 TPUv1 이후로는 FP 연산을 할 수 있도록 설계했다고 말한다. 이렇듯 mixed precision 설계를 갖추고 있는 것은 장점으로 작용할 것이다.
커스텀 ISA
Instruction Set Architecture. HW와 SW 사이의 인터페이스. 이로 칩이 어떻게 작동하는지 결정된다.
다양한 딥러닝 알고리즘 지원: CNN, LSTM, BERT
CNN은 이미지, LSTM은 시계열 데이터, BERT는 자연어에 쓰이는 딥러닝 모델이다. 서로 다른 딥러닝 알고리즘은 각각의 특징을 가지고 있기에, 한 가지에만 특화하는 것이 HW를 설계하기 더 쉽다. 그러나 범용성이 떨어져 새로운 모델이 등장했을 때 문제가 발생하는데, 동사의 칩은 비교적 넓은 범위의 모델을 구동할 수 있는 것으로 보인다.
성능 면에서 동사가 강조한 부분은 다음과 같다:
전성비 (TOPS/Watt)
FP16 기반 금융 알고리즘: >2.0 TFLOPS/Watt
FP16 기반 컴퓨터 비전 알고리즘: >2.0 TFLOPS/Watt
INT8 기반 자연어 알고리즘: >10 TOPS/Watt
ULL 서버 구축 가능
ION 4개를 합쳐 LightTrader 카드를 구성할 수 있다. 성능은 64TOPS, 20W, 50K Symbols/s.
LightTrader 카드 8장으로 서버를 구성하면 512TOPS, 300W, 400K Symbol/s의 성능을 낼 수 있다.
이를 통해 환기할 수 있는 중요한 사실은, ION이 연산을 처리할 수 있는 하나의 단위 (compute granule)라는 것이다. 즉, ION은 칩 1개로도 구동이 가능하지만, 여러 개 붙이면, 더 많은 연산을 처리할 수 있게 된다.
작은 컴퓨팅 조각을 붙이고 떼며 유연성을 확보하는 것이 동사의 설계 철학이며, ATOM과 차기작 REBEL을 다루며 그 사실이 더 명확해진다.
ATOM

ION은 퀀트를 전문적으로 다루는 월스트리트의 거대 금융 기업들만 관심을 가지는 니시(niche)한 제품이다. 반면 ATOM은 거대한 AI 추론 (inference) 하드웨어 시장에 도전한 야심작이다.
처음엔 빅테크 공룡들이 즐비한 AI 하드웨어 가속기 시장에 도전하는 것에 두려움이 있었다고 한다. 그러나 국내 2위 데이터센터 업체인 KT와 협력 관계가 가시화되고, 회사의 비전이 커지며 (“삼성으로부터 바톤을 받는 반도체 회사 되겠다”) 큰 시장에 도전하고 있다. 최근 KT 데이터 센터에 탑재된 ATOM이 동사를 뜨거운 감자로 만들어 준, 바로 그 칩이다.
ATOM의 스펙을 살펴보자. ATOM은 삼성파운드리 5nm EUV 공정으로 제작되었다 (삼파가 먼저 찾아왔다는 이야기). FP16에서 32TFLOPs, INT8/4에서 128/256TOPS의 성능을 보여주며, 64MB의 SRAM과 16GB의 GDDR6 (256GB/s) DRAM을 탑재했다. PCIe Gen5 (64GB/s)로 서버에 탑재되며, TDP는 60~150W이다.
the memory wall
ION과 다르게 메모리가 스펙에 추가된 것을 알 수 있다. 이는 칩의 목적성이 AI에 집중되었기에 자연스러운 일이다. 추론을 가속하기 위해서는 연산뿐 아니라, 모델의 파라미터를 가속기에 전달하는 (input/ouput 이하 I/O) 것이 필수적이기 때문이다. 메모리와 관련된 이야기는 앞으로 다룰 내용을 이해하는 데 필수적이기에 짚고 넘어가고자 한다.
딥러닝 모델을 함수로 표현하면, 추론은 함수의 모양과 특징을 저장해 두고, 새로운 X 값이 주어지면 함수를 저장한 곳에서 불러와 연산을 진행하고 Y 값을 출력하는 것이다.
컴퓨터에서 저장과 불러오기를 담당하는 것은 메모리이다. 메모리에서 값을 임시 저장하고 연산을 진행하는 프로세서에 전달한다. 따라서 대용량의 연산을 할 때 I/O를 담당하는 메모리의 대역폭이 중요하다. 아래 그림에서는 메모리를 창고 (왼쪽), 프로세서를 공장 (오른쪽)으로 표현한다. 창고와 공장 사이를 효율적으로 잇는 것이 중요하단 것은 자명해 보인다.
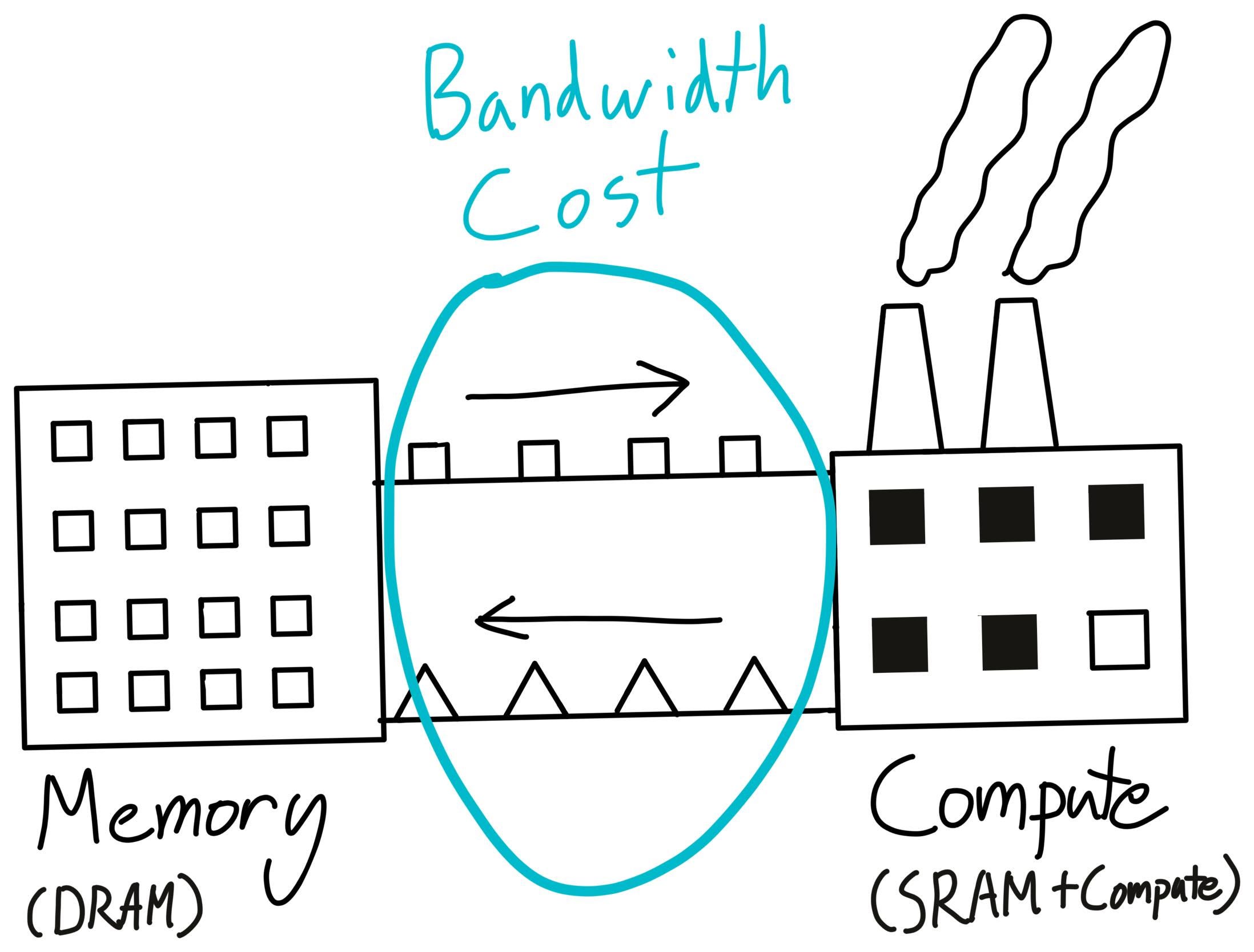
최근 딥러닝 모델의 일종인 트랜스포머 모델이 급부상하며 메모리의 대역폭과 속도가 더더욱 중요해지고 있다.
현재 가장 많은 수요는 chatGPT, 네이버 클로바와 같은 거대 언어 모델(LLM)에서 발생한다. 이 모델들은 대부분 decoder-only 트랜스포머로, 인풋을 기반으로 단어(토큰)가 생성되면, 이를 인풋 끝단에 연결하고(append), 다시 모델을 돌려 다음 단어를 생성하는 과정을 반복하며 작동한다.
이 프로세스를 실행하기 위해서는 모델의 모든 파라미터를 매번 메모리에서 읽어올 수밖에 없다. 함수로 설명하면, X1을 넣어 Y1을 얻었는데, Y2를 얻기 위해 필요한 X2에 Y1이 포함된 구조이다. Y1000까지 얻기 위해서는 건너뛰기 없이 함수를 1000번 불러와야 할 것이고, 이는 매번 메모리를 엑세스한다는 의미이다.
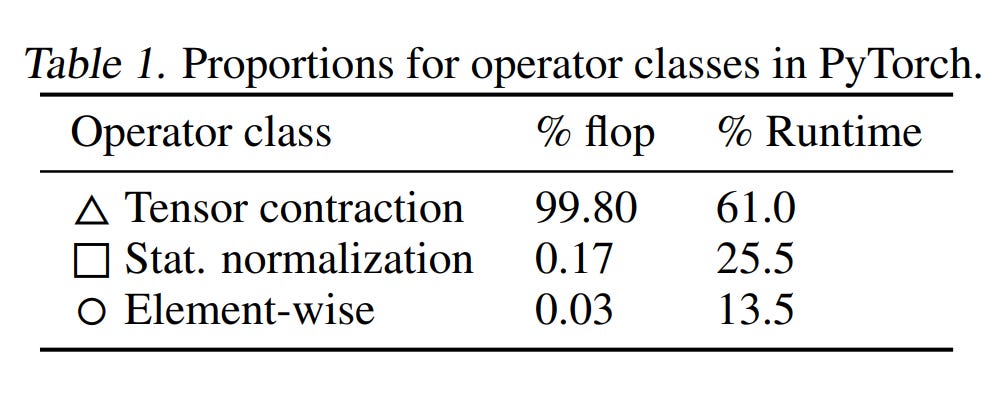
그런 이유에서 트랜스포머를 구동시킬 때 가장 큰 병목은 메모리의 대역폭이다. 아래 figure에서 세모로 표시된, Tensor contration은 행렬곱 연산으로, FLOPs (연산량)의 99%를 차지하지만, 런타임(작동 시간)의 60% 가량만 차지한다. 반대로, 메모리에서 값을 읽어와야 진행할 수 있는 정규화 (normalization)와 내적 (element-wise)은 연산량을 미미하게 차지하나, 런타임의 40%나 차지한다.
연산을 빨리 해도, 느린 메모리 I/O 때문에 전체 작동 시간에 큰 지연이 발생하고 있다.
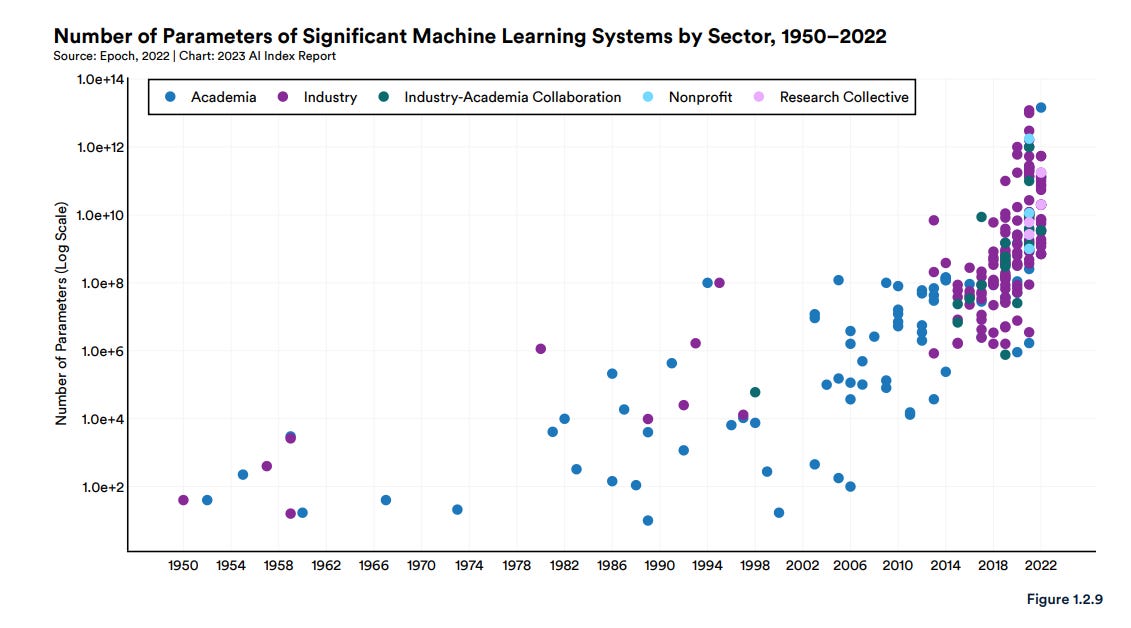
거기다 언어 모델의 크기는 나날이 커지고 있다. GPT-3는 175B의 파라미터로 구성되었고, GPT-4는 1.8T로 추정되며, 약 10배가 커졌다. 물론 OpenAI의 Sam Altman이 더 이상 모델 사이즈가 중요하지 않다는 의미심장한 말을 남겼지만, 앞으로 등장할 언어 모델은 적어도 1T개의 파라미터를 가질 것으로 예상된다.
이가 언어 모델에만 적용되는 이야기는 아니다. 스탠퍼드 HAI State of AI 2023 리포트를 살피면, 분야 전반에 걸쳐 파라미터 수가 로그 스케일로 커지고 있음을 확인할 수 있다.
1T 파라미터의 LLM을 기준으로 메모리 요구사항을 살펴보면, 1T개의 FP16는 총 2TB의 용량을 가지기에, 엄청난 양의 메모리와 대역폭이 필요함은 자명하다.
이를 해결하고자 하는 것이 HBM (High Bandwidth Memory, 고대역폭 DRAM)이다. 기존 G(raphic)DDR 메모리보다 고대역폭을 지니고 있기에, 지금까지 설명한 문제를 해소할 수 있다.
물론 메모리만 많다고 해서 모든 문제가 해결되는 것은 아니다. HBM 용량과 성능이 비례하면 좋겠지만, 칩과 메모리 사이의 통신뿐 아닌 칩 내부에서도 효과적인 통신이 필요하다. 이가 하드웨어 설계 역량을 그대로 보여주는 것이고, 값비싼 메모리를 쓰지 않고서도 연산 시간을 효과적으로 줄일 수 있기에 중요하다.
컴파일러를 통해 이런 병목을 해결하는 방법도 존재한다. 이는 아래 컴파일러 섹션에서 자세히 다룬다.
다시 돌아와서 몇 가지 특징을 살펴보자.
ION 코어 기반의 설계
앞서 언급한 ION을 컴퓨팅 단위로 활용한 설계이다.
ION을 여러 개 붙이며 생기는 성능 저하는 NoC(network on chip, 칩 내부의 코어 간 소통)를 통하여 완화했다. NoC는 박성현 대표가 박사 학위를 받은 분야이다.
고속 I/O
GDDR6 (not HBM), PCIe Gen5. 다른 폼팩터로 출시되지는 않았다. 이 설계에는 세미파이브의 SoC 플랫폼이 도움을 주었다.
16GB의 GDDR6 메모리는 256GB/s의 대역폭을 가지며, 이는 NVIDIA의 플래그십 H100에 사용된 3TB/s의 HBM에 비교하면 높은 수준은 아니다.
멀티 인스턴스
하나의 NPU를 여러 개로 나누어서 사용할 수 있다 (최대 16개로 쪼갤 수 있음). 개발자들을 위해 쉬운 예시를 들어보자면, GPU는 하나 달려있는데, nvidia-smi 하면 CUDA:0, 1… 15까지 나오는 것.
전성비
비전모델 (ResNet-50): 16 Inference/sec/Watt
언어모델 (BERT-Large): >3 Inference/sec/Watt
성능
MLPerf v3.0, Inference - Edge (Single Stream | Multi Stream | Offline)
비전 모델 (ResNet-50): 0.23ms | 0.43ms | 36427.9 samples/s
언어 모델 (BERT-Large): 4.3ms | N/A | 233.04 samples/s
MLPerf는 인공지능 반도체의 성능을 객관적으로 평가하기 위해 전 세계 다양한 기업과 연구 기관이 함께 만든 지표이다. 2023년 4월 공개된 v3.0 결과에서 ATOM이 좋은 성능을 기록하며, 언론의 주목을 받았다.
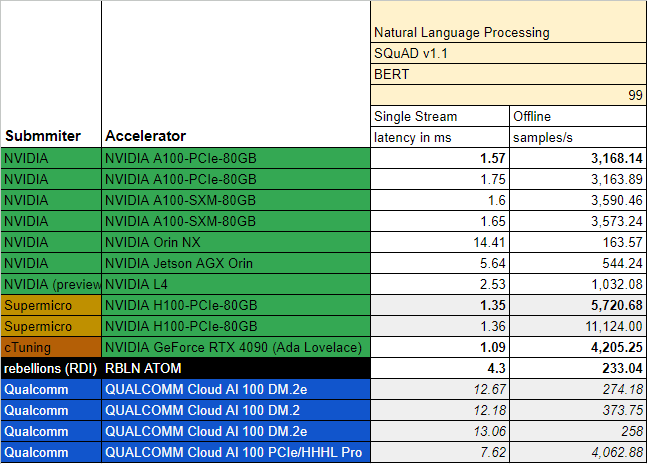
트랜스포머 모델인 BERT에서의 성능에 주목해 보자. Single Stream(좌측)에서 동사의 ATOM은 Qualcomm의 Cloud AI 100 PCIe를 크게 앞섰지만, NVIDIA의 L4 (전력 소모량 기준 동급)에는 못 미치는 성능을 보여주었다 (낮을수록 좋은 숫자).
MLPerf 지표 (용어, 의미)에 대해서는 아래 competition 섹션에서 더 자세히 다룰 것이다. 아직은, NVIDIA IS KING.
rebel
2024년 출시될 칩으로, NVIDIA가 A100과 H100으로 장악하고 있는 250W급 AI 반도체 시장을 정조준하고 있다.
박성현 대표의 업데이트에 의하면, rebel에서 H100 이상의 메모리 대역폭을 확보하고, 더 크고 빠르게 흘러들어오는 데이터를 처리하기 위한 내부 대역폭을 확보하기 위해 노력 중이라고 한다.
fe/be compiler
동사의 링크드인 소개는 “AI 반도체와 컴파일러를 설계하는 대한민국 스타트업입니다”이다. 그만큼, 동사에 대해 다룰 때 하드웨어만 다룬다면, 그건 반쪽짜리 그림만 보는 것이다.
컴파일러는 하나의 개발 언어 (일반적으로 high-level, 인간이 쉽게 작성할 수 있음)를 다른 언어로 (일반적으로 low-level, 0과 1로 된 기계어) 번역하는 소프트웨어이다.
컴파일러가 없거나 버그투성이라면, 직접 ISA(커널 코딩)를 다루어야 하고, 개발에 필요한 노력과 시간이 기하급수적으로 늘어난다. 그렇기에 편리하게 이용할 수 있는 bug-free 컴파일러를 고객사에 전달하는 것은 선택 아닌 필수이다.
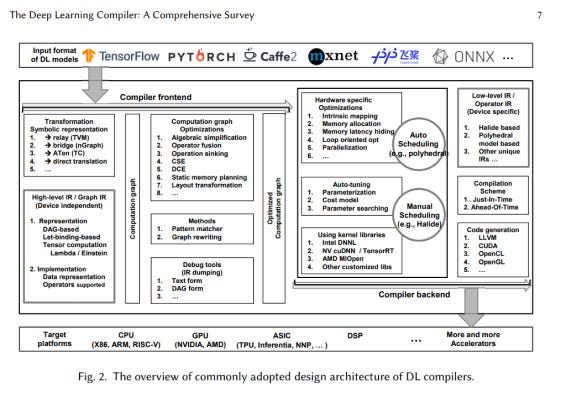
딥러닝 컴파일러를 제작하는 것은 매우 복잡한 일이다 (위 figure 참고). 잠시 기술적인 이야기를 해보자.
컴파일러는 프런트엔드와 백엔드로 구성된다. 먼저 프런트엔드부터 살펴보자. 유저들이 다양한 라이브러리를 활용하여 딥러닝 모델을 제작하기에 (e.g. 텐서플로우, 파이토치 등) 이를 적절하게 그래프 IR (Graph Intermediate Representation, 그래프 형식의 중간 표현)으로 변환해야 한다. 여기서 IR 그래프를 적절히 최적화한 후 컴파일러 백엔드로 넘긴다. 아래 언급할 연산자 융합 테크닉도 이 과정에 포함되어 있다.
컴파일러 백엔드에서는 HW에 특화된 최적화 및 스케줄링이 일어난다. 그 결과 연산자 IR (Operator Intermediate Representation, 연산자 형식의 중간 표현, 더 기계어에 가까워졌기에 Low-level IR이라 부르기도 함)이 탄생하고, 그를 기반으로 HW에 전달할 수 있는 코드가 생성된다.
요약하면:
모델 → 그래프 IR → 그래프 최적화 → HW 특화 최적화 및 스케줄링 → 연산자 IR → 컴파일 → 코드 → HW
버그 없는 컴파일러를 제공하는 것 다음으로 중요한 것은 바로 컴파일러의 성능이다. 컴파일러가 최적화를 엉망으로 한다면, 좋은 프로세서를 갖추었다고 해도 그 컴퓨팅 파워를 적절하게 활용할 수 없다. 또한, 컴파일러를 최적화하면서 메모리 대역폭 문제를 일부 해결할 수 있다.
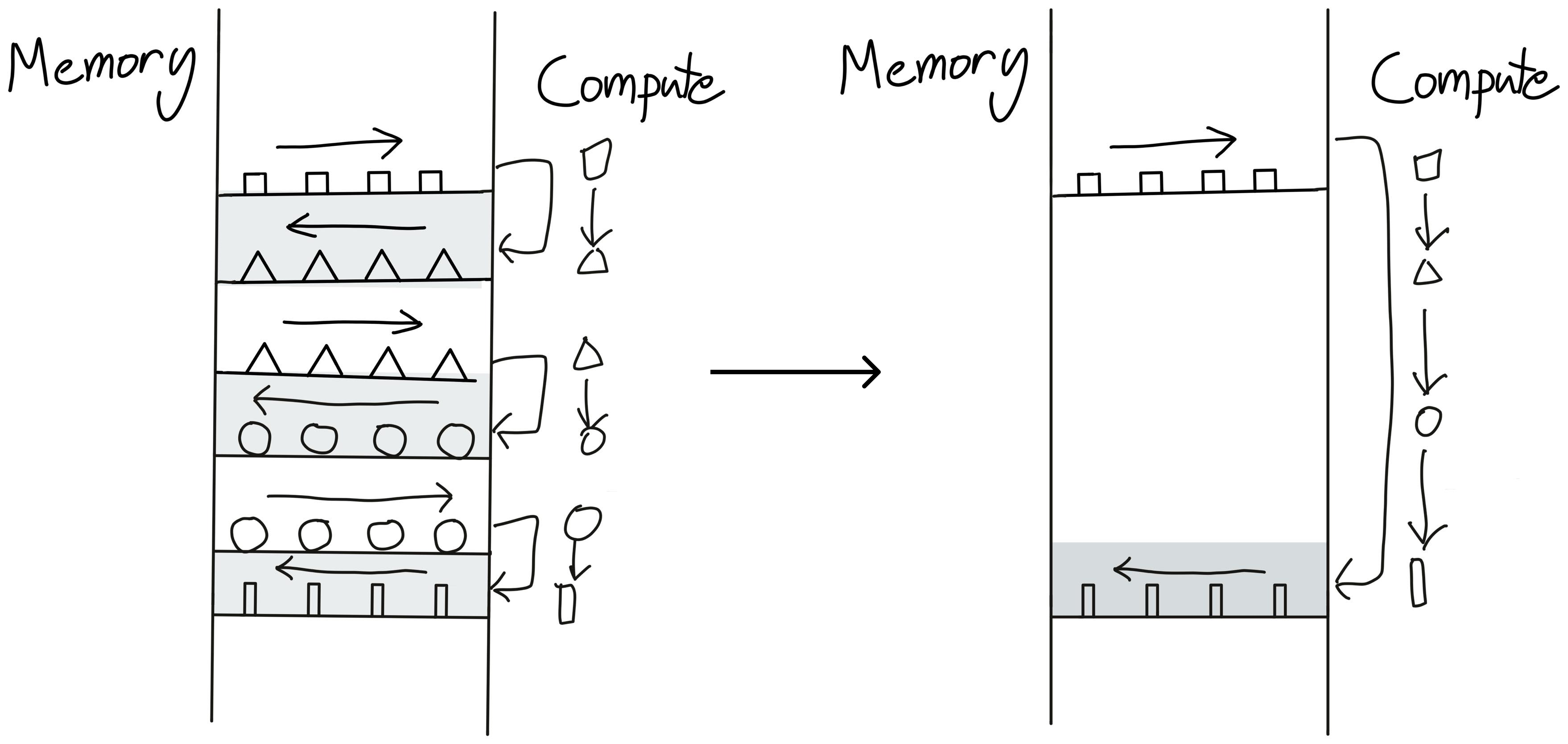
별도의 조정이 없으면, 하나의 연산을 할 때마다 그 결과를 메모리에 보냈다가 돌려받아야 한다. 결과적으로 매번 메모리 대역폭에서 생기는 병목에 시달리게 된다. 이를 해결하기 위해서 여러 연산자를 하나로 합치는, 연산자 융합 (operator fusion)이라는 테크닉이 발전했다. 상단 그림에서 3개의 연산을 하나로 융합함으로써 3번의 왕복을 1번으로 줄인 것을 확인할 수 있다.
이렇게 연산자를 합치다 보니, 연산자의 숫자가 크게 불어났다 (아래는 연구자들이 가장 많이 사용하는 PyTorch 라이브러리의 연산자 구분).
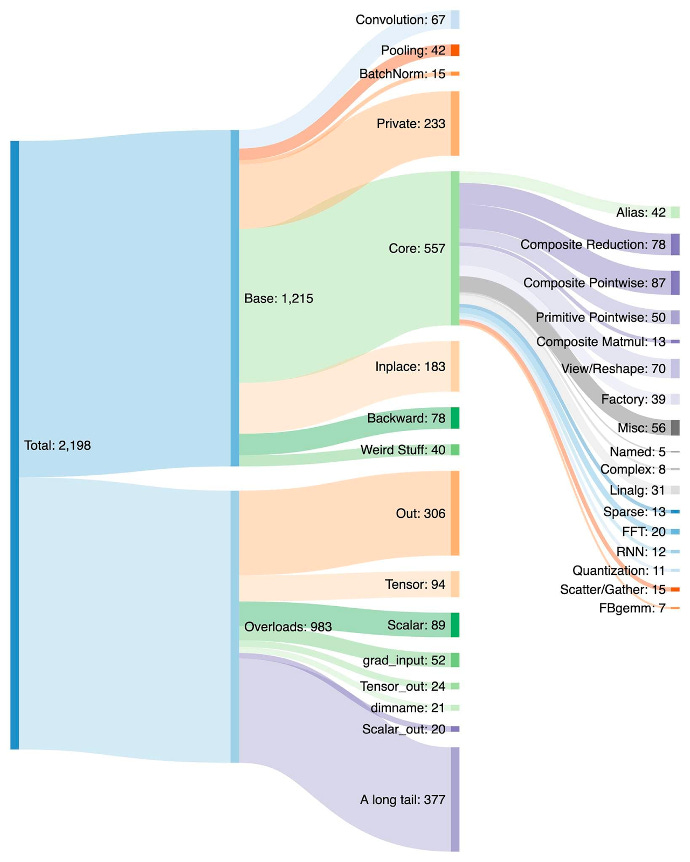
NVIDIA와 CUDA SW 스택은 이 과정에서 쓰이던 디폴트 하드웨어였다. 자연스레 NVIDIA GPU와 호환되게 커널 코드가 작성되었고, 이가 NVIDIA의 강력한 SW 해자(moat)의 근원지 중 하나이다.
간단하게 살펴보았지만, 컴파일러를 “잘” (특히 NVIDIA보다 더 잘) 만드는 건 어려워 보인다. 그렇기에 NPU 회사들은 NVIDIA의 완벽에 가까운 SW 스택에 경쟁하기 위해 협력하고 있다. 그 결과물이 Apache TVM이라는 오픈 소스 컴파일러이다. TVM은 오픈 소스 컴파일러 중 GPU에서 가장 높은 성능을 보여준다.

백지에서 컴파일러를 개발하는 것은 불가능에 가깝기에, 동사는 TVM에 기반하여 자체 컴파일러를 개발하고 있다.
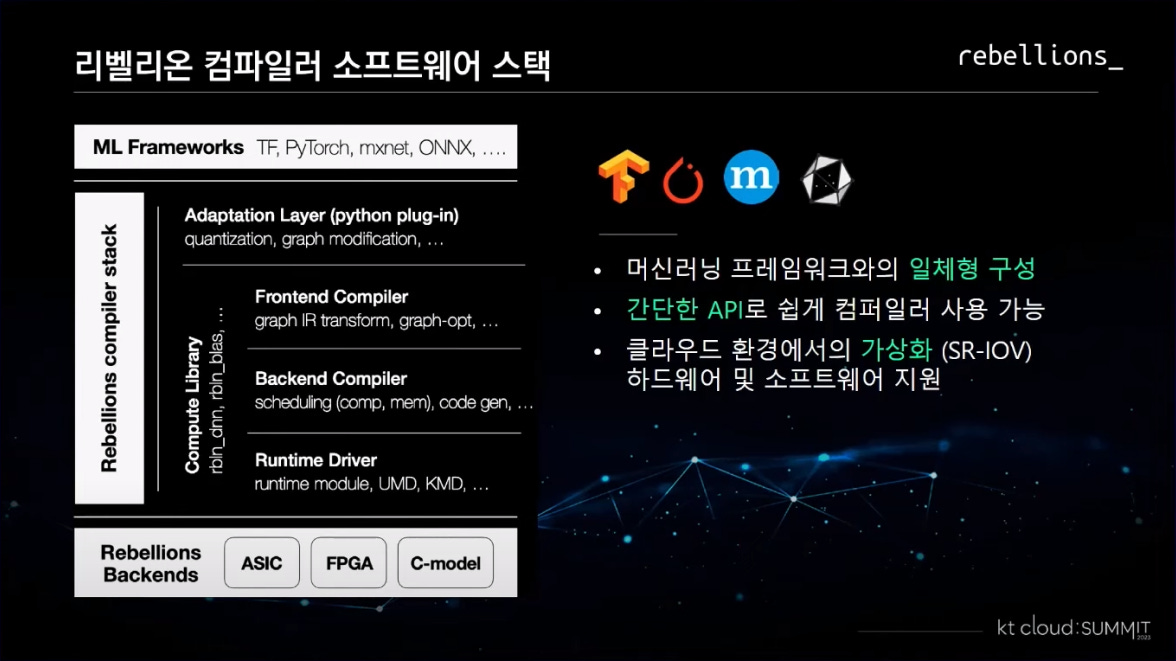
TVM과 동일하게, 다양한 ML 프레임워크와 호환되고, 앞단에 파이썬 플러그인으로 양자화와 그래프 수정을 제공한다. 이후 컴파일러를 거쳐, 런타임 드라이버로 전달되어 동사의 하드웨어로 전달된다. 클라우드 환경에 발맞추어 가상화 하드웨어 및 소프트웨어를 제공하는 것도 특징 중 하나이다.
RBLN SDK (컴파일러, 런타임, 드라이버)의 성능을 판단하는 것은 외부자 입장에서 불가능하다. 그러나 이 도구들이 1) 추론의 성능과 2) 개발의 난이도를 크게 좌우하기에, 동사의 경쟁력을 결정하는 큰 요소가 될 것이다.
market
customer
ION은 앞서 언급한 것과 같이, 인공지능 퀀트 트레이딩을 하는 금융회사들이 타겟 고객층임이 명확하다.
ATOM은 대규모 데이터 센터 업체를 타겟하는 제품으로 보인다. ATOM의 제품 설명서의 일부를 발췌했다:
ATOM utilizes the silicon-proven neural core, ION, as a compute granule that scales up with perfect linearity for largescale inference operations required in edge computers and datacenters.
엣지 컴퓨터와 데이터 센터를 염두에 두고 제작하였다면, 둘 중 어떤 곳이 더 큰 고객이 될까? 이에 대해 답하기 위해서 앞서 다룬 메모리 문제로 돌아가 보자.
최근 수요가 폭발하고 있는 LLM의 경우, 파라미터 숫자 때문에 메모리가 적어도 수십GB 탑재되어야 한다고 언급했다. 그러나, 우리가 사용하는 랩톱만 해도, 많아야 램이 16GB이다. 핸드폰으로 내려가면, 4GB까지 메모리가 떨어지기 마련이다. 그 뜻은, 작은 엣지 디바이스에서 언어 모델을 돌리는 건 불가능하다는 뜻이다.
그보다 큰 문제는 엣지 디바이스의 타이트한 에너지 제약이다. 소비자들이 흔히 구입하는 엣지 디바이스 (e.g. 컴퓨터, 핸드폰, 스마트가전)에는 일반적으로 전기를 많이 잡아먹을 만한 칩이 탑재되지 않기에, 사용할 수 있는 전력의 양에 한계가 있다. 아무리 ATOM의 전성비가 양호해도, 일반적인 엣지 디바이스에서 감당할 수 있는 수치라고 보기는 어렵다.
글로벌 모바일 AP 제작사들이 이미 SoC로 NPU를 프로세서에 집어넣고 있다는 사실도 상기할 필요가 있다. 우리 핸드폰 속에도 이미 작은 규모의 NPU가 존재한다 (애플 bionic A16에는 16코어, 17TOPs의 성능을 내는 NPU가 탑재되어 있다). 작은 인공지능 모델의 구동은 이미 모바일 AP에서 해결하고 있다. 이 시장에 동사가 뛰어드는 건 쉽지 않아 보인다.
위와 같은 이유로 동사가 집중해야 할 시장은 데이터 센터로 보인다.
엣지 디바이스에서 돌리기 어려운 큰 워크로드는 자연스럽게 클라우드, 즉 데이터 센터로 전해진다. OpenAI chatGPT, 구글 Bard와 같은 파운데이션 모델 (foundation model)을 사용하는 엔드 유저가 폭발적으로 늘어나며, 데이터 센터 업체들은 AI 하드웨어 가속기 구매에 열을 올리고 있다.
데이터 센터 중에서도 큰 규모의 고객사를 타겟하는 것이 현실적으로 보인다. 그 이유는 동사의 칩은 기본적으로 ASIC, 즉 주문 제작 반도체라는 것이다. NVIDIA와 같은 범용성을 갖추며 동일 성능을 뽑아내는 것은 불가능하다. 그렇기에 고객사에 최대한 맞추어 칩과 SW를 구성해야 NVIDIA에 아성에 맞설 수 있다.

애플(Apple Silicon)과 테슬라(Dojo, FSD 등)를 보면, 단순히 성능이 좋은 칩을 설계한다기보다, 기업의 상황에 알맞게 특화된 반도체를 설계하며 거대한 해자를 구축한다. 애플은 iOS, 테슬라는 테슬라 소프트웨어라는 자체 OS를 가지고 있기에 더 큰 효과를 얻을 수 있다.
데이터 센터향 칩의 경우, OS 제작까지 이어지지 않을 수는 있으나, 각 데이터 센터가 서비스하는 모델에 따라서 특화될 것으로 보인다. 예로 Azure가 GPT향 추론 칩을 디자인한다면, 동사보다 우위를 가질 수밖에 없다. OpenAI와 Microsoft는 전략적 협력관계를 맺어 서로를 위해 SW와 HW를 조정하여 성능을 끌어올릴 수 있기 때문이다.
이런 커스터마이징 작업에는 시간과 인력이 대거 투입된다. 고객사에서 사용하는 AI 모델과 코드에 대한 이해도가 필요하고, 그에 맞추어 HW와 SW를 수정하고 버그를 고치는데 적어도 수개월은 필요하다. 시간이 지나면서 더 높은 성능의 HW로 교체할 소요도 존재한다. 즉, 작은 규모의 계약에 이런 서비스를 제공하는 것은 규모의 경제가 나오지 않는다.
그렇기에 큰 고객사와 대규모 계약을 체결하고 커스텀 서비스를 제공하며, 가성비와 전성비를 무기로 삼아 NVIDIA의 약점을 공략해야 할 것이다. 그뿐 아니라, KT와 동사의 관계와 같이 고객사-제공자 관계를 뛰어넘은 파트너십을 맺어야 할 것으로 보인다.
market size
가트너에 의하면, 2022년 AI 반도체 시장은 58조 규모이고, 2027년까지 110조 규모까지 커질 것으로 전망된다.
추론과 학습, 엣지와 데이터 센터에서 AI 반도체 시장은 어떨까?
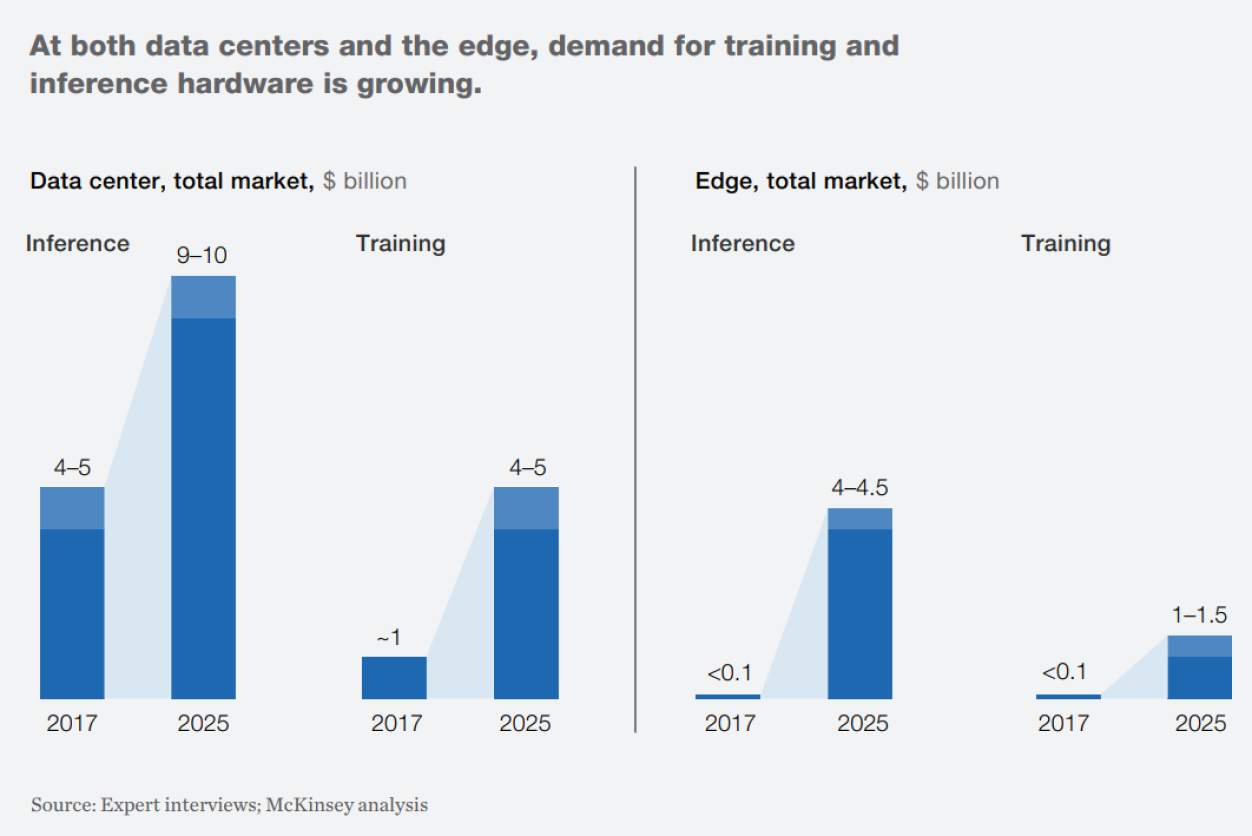
맥킨지에서 공개한 자료에 의하면, 데이터 센터 시장의 크기가 엣지 시장의 크기보다 클 것이고, 추론이 더 큰 시장이 될 것이다. 학습은 연구자들이 진행하기에 전체 물량에 한계가 있지만, 추론은 누구나 사용할 수 있으므로, 상방이 뚫려있기에 이런 추정은 자연스럽게 느껴진다.
동사가 타겟하는 TAM은 글로벌 AI 추론 하드웨어 시장일 것이고, SAM은 그 중 데이터 센터에 탑재하는 칩, SOM은 KT와의 협업으로 공략하고 있는 국내 AI 추론 데이터센터 시장으로 보인다.
business model
동사의 비즈니스 모델은 반도체를 데이터 센터나 금융기업에 판매하는 것이다.
ION의 계약 체결 소식은 없고, AI 하드웨어의 중요성이 급부상하며, 동사의 주 매출은 ATOM과 다음 세대의 REBEL과 같은 추론향 AI 하드웨어 가속기에서 발생할 것으로 보인다.
2023년에는 KT와 협업을 통해 실질적인 칩 공급을 시작하고 있고, AI 칩 춘추전국 시대가 유지되는 동안 글로벌 시장에 뛰어들어 고객사 다각화 및 스케일업을 추진할 것으로 보인다.
GTM 전략을 명확하게 파악하기는 어려우나, 가장 강력한 세일즈는 좋은 성능이 될 것으로 보인다. 글로벌 데이터센터 업체들이 세일즈 컨텍을 받을 때 MLPerf 지표와 같은 성능을 요구하에 이부터 압살하는 것이 시작이다.
그다음부터는 C-level의 역량에 달려있다고 생각한다. 계약 규모가 큰 만큼, 영업 사원보다 C-level이 직접 딜을 진행할 것이다. 미국에서 커리어를 쌓아온 박성현 대표와 오진욱 CTO와 루닛에서 글로벌 확장 경험이 있는 김효은 CPO가 있기에 여타 국내 경영진보다 엣지가 있다고 생각한다.
traction

2020년 9월 창업 후 1달 만에 카카오벤처스가 리딩한 시드 펀딩에서 제품 없이 55억의 투자금을 받으며 화제가 되었다. 1년이 조금 더 지난 2021년 말, 첫 제품 ION을 TSMC 7nm로 테이프-아웃했다. 현재까지 QA를 진행하고 있다만, 아직 계약 건은 없다.
2022년 6월, ION을 기반으로 설계한 ATOM을 삼성파운드리 5nm EUV로 테이프-아웃했다. 이와 동시에 620억 규모의 시리즈A 펀딩을 받았고, 1달 후에 KT에게 300억의 전략적 투자를 받으며 데이터 센터 시장 공략의 파트너를 찾았다. 다음 해 2월, ATOM이 공식 출시되었다.
2023년 4월, MLPerf v3.0 벤치마크를 통해 ATOM의 성능이 공개되었다. 글로벌 경쟁력을 갖추고 있는 성능 지표를 보여줌으로써 동사에 대한 기대감이 증폭되었다.
5월에는 정부가 지원하는 ‘초격차 스타트업 1000+’에 선정되며, 정책 보증과 수출 지원 연계를 받게 되었다. 6월에는 대통령 주관의 반도체 국가전략 회의에 AI 반도체 기업을 대표하여 참석하며, 정부와 협력 관계를 키워가고 있다. 동사는 국산 AI 반도체를 이용하여 구축하는 K-클라우드 사업에도 참여하며, 총 8.9PFLOPs 크기의 서버를 구축할 예정이다.

동시에 KT와의 협력에도 속도가 붙고 있다. 6월, 국내 첫 클라우드 기반 NPU 인프라에 동사의 ATOM이 탑재되어 현재 서비스 중이다. 이로써 최초의 매출이 발생할 것으로 예상된다.
이는 향후 글로벌 세일즈에서 중요한 레퍼런스가 될 것이다. 큰 규모의 데이터 센터에서 ATOM 칩들이 1년가량 좋은 퍼포먼스를 냈다면, 구매자 입장에서 안정성과 성능 (컴퓨팅과 TOC) 면에서 의구심이 줄어들 것이다.
KT와 리벨리온은 서로의 HW, SW, 데이터를 고려하여 반도체를 맞춤 제작하여, 더 좋은 성능을 끌어낼 계획을 하고 있다.
24년에는 초거대 AI를 작동시키기 위한 칩 리벨을 준비 중이며, KT와 협업을 통해 ATOM을 계량하여 ATOM+를 내놓을 예정이다.
지금까지 동사에 대해서 전반적인 내용을 살펴보았다. AI 칩 춘추전국 시대에서 동사의 경쟁력과 약점은 무엇이며, 어떤 경쟁자들과 맞서야 하는지 이어지는 글에서 다루고자 한다. 전체 기업분석 글은 Pinpoint Research에서 곧 만나볼 수 있다. 위대함을 좇는 비상장 기업들에 대해서 더 읽어보고 싶다면, 구독하시길.
Special thanks to Juhyun Cho, Deokhaeng Lee, Taeheon Song, and Kyunghwan Min.

프런티어 by 김도엽을 읽어주셔서 감사합니다.
안전한 슬롯 사이트는 라이센스가 부여되고 규제되어 공정한 플레이와 안전한 거래를 보장합니다. SSL 암호화를 사용하여 데이터를 보호하고, 긍정적인 사용자 리뷰를 얻었으며, 안정적인 게임 경험을 위해 신속한 고객 지원을 제공합니다.
https://rcgormangallery.com/
반도체를 설계만 하는 스타트업이라니 기가 막히네요